安装与使用
- :服务端 + 客户端
- :源代码
- :客户端(基于Qt5的跨平台Redis桌面管理软件,C++编写,响应迅速、性能好,但不支持数据库备份与恢复)【备用客户端:RedisPlus 3.2.0】
具体使用:
- 服务端启动:将命令 redis-server.exe redis.windows.conf 写入 .bat 文件,直接运行 StartWithConf.bat 启动服务端;
- 客户端启动:直接运行 redis-cli.exe 即可;
redis.windows.conf:配置文件redis-benchmark.exe:Redis读写性能测试工具redis-check-aof.exe:aof修复检查日志redis-check-dump.exe:dump检查数据库文件redis-cli.exe:Redis客户端程序redis-server.exe:Redis服务器程序StartWithConf.bat:启动Redis
配置文件
redis.windows.conf
Redis服务端的运行参数全部靠配置文件实现,此处详细介绍Redis配置文件的几个重要参数:
// networkbind 127.0.0.1:绑定地址(外网连接:0.0.0.0) port 6379:默认绑定本机的6379端口;timeout:连接超时时间(秒)requirepass pass:配置redis连接认证密码// generalloglevel debug/notice/warning/verbose:日志级别(开发测试/生产环境/只记录警告错误信息/详细信息)logfile ./Logs/redis_log.txt:日志文件保存路径databases 16:数据库数量,默认0// snapshottingsave TimeInterval ChangeCnt// append only modeappendonly yes:开启命令日志模式;// limitsmaxclients 64:最大连接数,0为不限制maxmemory:内存清理临界值maxmemory-policy volatile-lru:内存清理采用的默认策略,对设置过期时间的key进行LRU算法删除
服务命令
ping:启动服务连接情况info:查看server/client配置信息info commandstats + config resetstat:显示/清除名次调用统计信息config get/set:获取/设置配信息flushdb/flushall:删除当前所选/所有数据库中的所有keysave/bgsave:数据保存到硬盘/异步保存lastsave: 上次成功保存到磁盘的unix时间戳dbsize:查看所有key的数目 get/set和mget/mset:获取/设置键incr/decr和incrby/decrby:自增/自减exists/type key:键key是否存在/键类型expire key secondTime:设置键的过期时间rename oldKey newKey:重命名ttl key:键key的剩余存活时间select db_index:选择数据库move key db_index:将键key移动到指定数据库
基本概念
Redis是典型的NoSQL数据库服务器,其License是Apache License、完全免费。首先看下内存数据库的基本概念:
内存数据库
In-Memory DataBase,以内存为主要存储介质的数据库.
- 所有的表及索引在内存中、消除I/O瓶颈,为访问内存设计最佳访问方法和索引模式,读写速度快、性能好;
- 内存数据库的容量大小受物理内存的限制;
- 安全性问题是硬伤,支持根据策略与磁盘数据库进行数据同步,以及数据库的可靠性恢复机制;
Redis
REmote DIctionary Server(远程字典服务),远程内存数据库(Memory Database + Data Structure Server),开源的使用ANSI-C语言编写、支持网络、可基于内存亦可持久化的日志型、高性能的key-value数据库,Redis不预定义且不使用表,适应高并发、海量数据存储场景。
- A persistent key-value database with built-in net interface written in ANSI-C for Posix systems.
- Redis is an open source, BSD licensed, advanced key-value cache and store.
下面是Redis支持的5种类型数据结构的内部图解(图一):

redisObject 对象是Redis内部的核心对象,用于表示所有的key和value
typedef struct redisObject { unsigned type:4; // 数据类型 unsigned encoding:4; // 编码方式 unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; // 对象的引用计数 void *ptr; // 指向真正的存储结构} robj; 其中,REDIS_LRU_BITS 表示当内存超限时采用 LRU 算法清除内存中的对象。redisObject对象的创建在object.c文件中:
robj *createObject(int type, void *ptr) { robj *o = zmalloc(sizeof(*o)); o->type = type; o->encoding = OBJ_ENCODING_RAW; o->ptr = ptr; o->refcount = 1; /* Set the LRU to the current lruclock (minutes resolution). */ o->lru = LRU_CLOCK(); return o;} 具体内存结构示意图(图二):
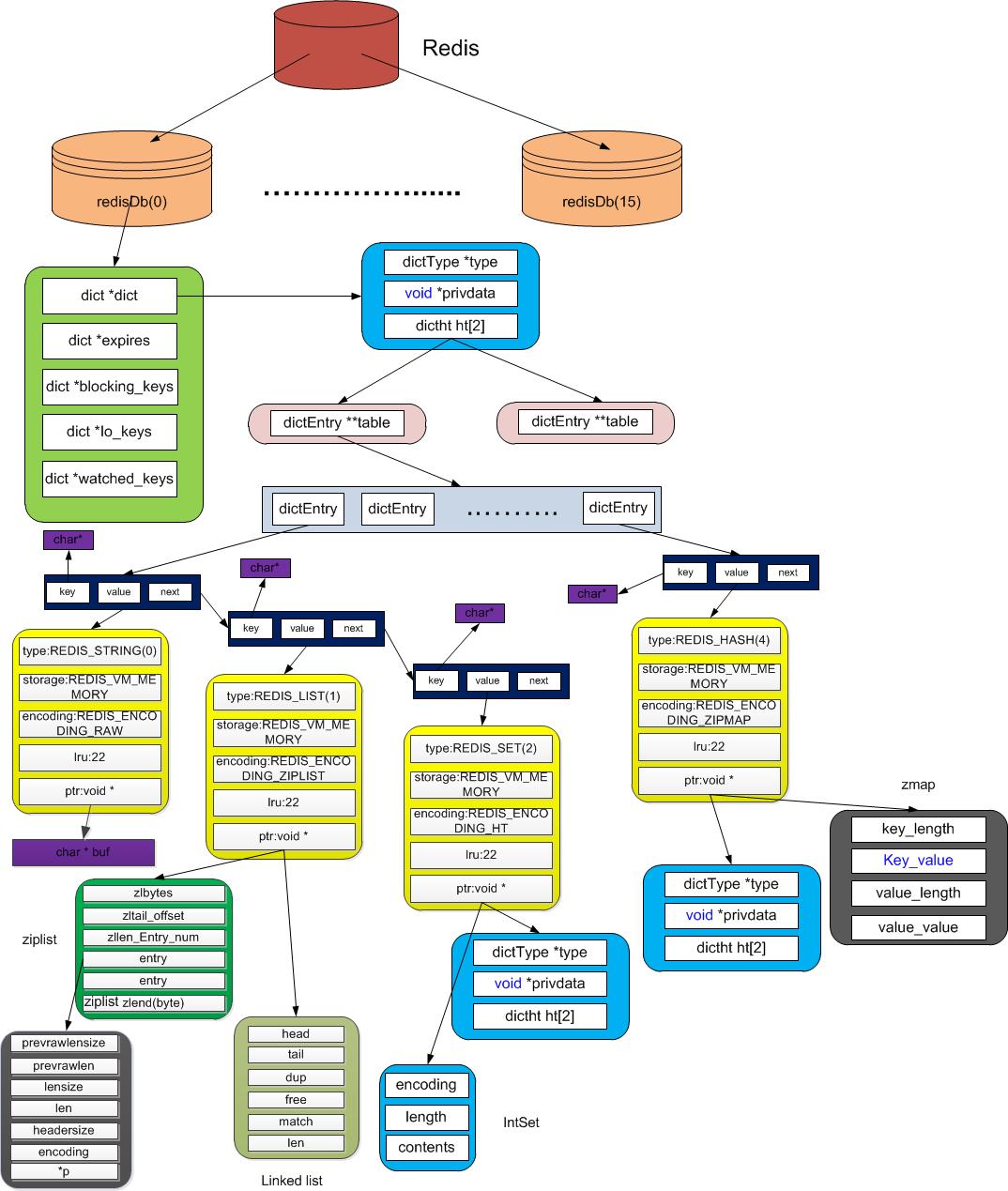
参考:; ;
特点
- 全部数据In-Momory,作为Memcached的替代者;
- key-value存储系统(Key:数据检索的唯一标识、Value:数据存储的主要对象),支持多种类型的value(数据结构服务器);
- redis的起点是cache,缓存,高速缓存;
- 数据存储于内存中或被配置为使用虚拟内存;
- 持久化特性(Persistence):可以持久化到磁盘(周期性把更新数据写入磁盘或把修改操作追加写入记录文件);
- 主从复制特性(Master/Slave Replication):负载均衡,扩展读性能;
- 客户端分片(Client-Side Sharding):数据划分为多个部分,扩展写性能,线性级别的性能提升;
- 支持各种不同方式的排序;
- 支持简单的事务(仅实现一次性执行多条命令的功能,不支持回滚);
- 支持设置数据过期时间;
内存优化
- string和数字:Redis内部维护一个数字池,可以节省存储空间,默认 REDIS_SHARED_INTEGERS = 10000
- 复杂类型的存储优化:Redis内部使用紧凑格式存储数据(适合集合包含的Entry不多并且每个Entry包含的Value不是很长的情况),遍历复杂度下降为O(n)、但节省存储空间。以ZIPMap的数据结构为例:

其中,字段free用于冗余空间,空间换时间、一定情况下避免插入操作引起的扩容操作。
- list、set、hash采用特殊编码,优化存储空间;
- byte、bit级别的操作:getrange/setrange、getbit/setbit以及bitmap高效存储;
Redis .vs. Memcached
- 两者均是高性能键值缓存服务器,Memcached只提供数据缓存服务,Redis提供数据缓存和持久化;
- Memcached:多线程服务器;Redis:单线程服务器,部分性能通过多线程实现;
- Memcached只支持普通字符串键;Redis提供丰富的数据存储结构,同时支持主数据库(Primary Database)+ 辅助数据库(Auxiliary Database)使用;
- Memcached:预分配内存池方式,Redis:现场申请内存的方式存储数据、且可以配置虚拟内存
数据类型
string

list
双向链表、允许重复,支持lpush/rpush和lpop/rpop;实现消息队列等;

set
不允许重复,内部是哈希表实现、查找/删除/插入均O(1); 集合提供SINTER、SUNION、SDIFF分别支持交集、并集、差集操作。

hash
键值对(父键+子键:值)。存储键key的多个属性数据,完全可以用Json格式存储、直接当作string类型操作,但对性能有影响,所以Redis提出Hash类型。

如下,图一是普通的key/value结构,需要封装一个对象保存value的信息;图二是Redis的Hash类型:
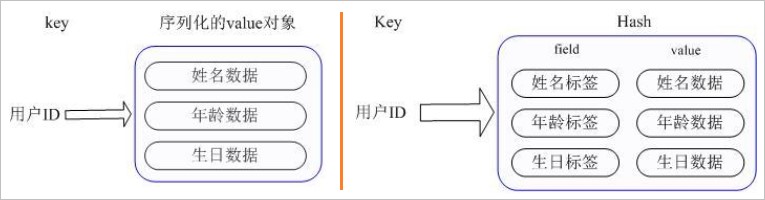
zset
有序键值对(父键+成员:分值),键值对实际是成员和分值(Member-Score)的映射关系(字符串成员member与浮点数分值score之间的有序映射,按分值大小排序),分值必须为浮点数; 既可以根据成员访问元素(同散列),又可以根据分值按序访问元素结构。

持久化
内存提供主存储支持、硬盘作持久性存储。默认开启RDB模式,默认优先加载AOF文件。一次性将数据加载到内存中,一次性预热。
问题:当服务器被关闭时,服务器内存存储的数据将何去何从?
RDB .vs. AOF
- RDB方式二进制方式存储数据,文件较小且格式紧凑(RDB文件的存储格式和Redis数据在内存中的编码格式一致)、加载速度快;AOF方式文本文件追加写操作命令,文件较大、信息冗余,加载速度慢,但rewrite命令会压缩aof文件;
- RDB方式按配置的save策略实现定期批量数据存储、效率相对较高;AOF方式准实时日志记录、效率相对较低;
- 相比RDB方式,AOF方式可靠性较高、最少的数据丢失和较高的数据恢复能力;
不重启Redis从RDB模式切换到AOF模式 :
redis-cli> config set appendonly yes:启用AOFredis-cli> config set save "":关闭RDB
==>:; ;
RDB
半持久化模式(快照方式:File-Snap-Shotting,即时间点转储:Point-in-Time Dump),Redis DataBase,将数据先存储在内存,当直接调用save/bgsave命令时或数据修改满足设置的save条件时触发bgsave操作,将内存数据一次性写入RDB文件。比较适合灾难恢复(Disaster Recovery),若Redis异常crash,最近的数据会丢失。
rdbcompression yes:创建快照时对数据进行压缩 dbfilename dump.rdb:快照名称dir ./saveFile/:快照保存路径(AOF文件存放目录)
原理:Copy-on-Write(写时复制)技术
- Redis forks;
- 子进程将数据写到临时RDB文件中;
- 当子进程完成写RDB文件,用新文件替换旧文件;
该原理保证任何时候复制RDB文件都是绝对安全的。
AOF
全持久化模式(日志方式),Append-Only-File,将数据存在内存,同时调用fsync将本次写操作命令进行日志记录到aof文件,基于Redis网络交互协议的由Redis标准命令组成的可识别的纯文本文件,只允许追加不允许改写。
写策略:默认并推荐 appendfsync everysec ,速度和安全兼顾。
- appendfsync always:每提交一个修改命令调用fsync刷新到AOF文件,非常慢、但非常安全;
- appendfsync everysec:每秒调用fsync刷新到AOF文件,很快、但可能会丢失一秒以内的数据;
- appendfsync no:依靠OS被动刷新、redis不主动刷新AOF,最快、但安全性差;
AOF最关键的配置就是关于调用fsync追加日志文件持久化数据的频率。磁盘空间满、断电等情况不会影响日志的完整性和可用性。
保存:支持2种方式
- 调用flushaofbuf,把aof_buf中的命令写入aof文件,再清空aof_buf,进入下一次loop;
sds aof_buf; /* AOF buffer, written before entering the event loop */
- aof_rewrite:根据现有的数据库数据反向生成命令,然后把命令写入aof文件中;
加载
fakeClient = createFakeClient(); // 创建伪客户端while(命令不为空) { // 获取一条命令的参数信息 argc, argv . . . // 执行 fakeClient->argc = argc; fakeClient->argv = argv; cmd->proc(fakeClient);} AOF重写
bgrewriteAOF,重新生成一份AOF文件,新的AOF文件只包含对同一个值的多次操作的最后一条记录(可以恢复数据的最小指令集),过程和RDB类似(Copy-on-Write机制):
- fork一个子进程,直接遍历旧的AOF文件,将数据写入新的AOF临时文件;
- 在写新文件过程中,所有的新的写操作日志记录在内存缓冲区中、同时会写入到原有的AOF文件中;
- 完成写新文件操作后,发出信号通知父进程将内存缓冲区中的写指令一次性追加到临时AOF文件中;
- 追加完毕,Redis将临时AOF文件作为新AOF文件代替旧AOF文件(调用原子性的rename命令用新的AOF文件取代老的AOF文件);
当同时满足以下2个条件时触发rewrite操作:
auto-aof-rewrite-percentage 100 // 当前写入日志文件的大小占到初始日志文件大小的某个百分比时触发rewriteauto-aof-rewrite-min-size 64mb // 本次Rewrite最小的写入数据量
注意,bgrewriteaof和bgsave不能同时执行,避免两个Redis后台进程同时对磁盘进行大量的I/O操作。
修复
Redis提供 redis-check-aof.exe 工具支持日志修复功能:
- 备份坏的AOF文件;
- 运行redis-check-aof –fix修复坏的AOF文件;
- 用diff -u对比两个文件的差异,确认问题点;
- 重启Redis,加载修复后的AOF文件;
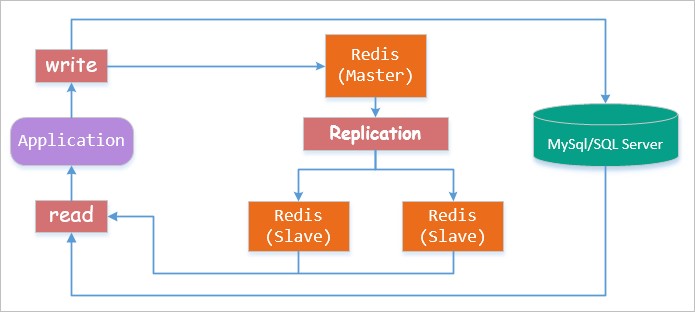
主从机制
master-slave,为了加强持久化机制,在持久化基础上Redis提供复制功能:将一个主服务器(master)数据自动同步到多个从服务器(slave),实现主从同步:
- 纯粹的冗余备份
- 提升读性能
具体地:
- 启动从服务器,先向主服务器发送SYNC命令;
- 主服务器收到SYNC命令后fork子进程开始保存快照,期间所有发给主服务器的命令都会被缓存到内存;
- 快照保存完成后,主服务器把快照和缓存的命令全部发送给从服务器;
- 从服务器保存收到的快照文件并加载到内存中,然后依次执行收到的缓存命令;
在主从同步过程中(异步实现),从服务器不会阻塞,期间默认使用同步之前的数据继续响应客户端命令。主从机制支持增量同步策略,降低连接断开的恢复成本。
具体应用中通常是:Redis+MySQL
发布订阅机制
publish-subscribe,观察者模式,订阅者(Subscriber)订阅频道(Channel),发布者(Publisher)将消息发到指定频道(Channel),通过这种方式将消息的发送者和接收者解耦,可以实现多个浏览器之间的信息同步和实时更新。
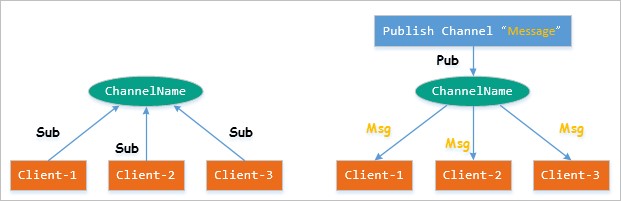
- 消息的传递是多对多的;
- 支持模式匹配;
- 运行稳定、快速;
publish myChannel “xxx”:发布 subscribe myChannel:订阅unsubscribe myChannel:取消订阅
Redis的Pub/Sub模式允许动态的Subscribe/Unsubscribe,提高系统的灵活性和可扩展性。
其他
排序
问题:数据库支持排序,为什么要把排序功能放在缓存中实现?
- 排序会增加数据库的负载,难以支撑高并发的应用;
- 在缓存中排序不会遇到表锁定的问题;
sort key [BY pattern] [LIMIT offset cnt] [GET pattern [GET pattern ...]] [asc | desc] [ALPHA] [STORE destination]
- by:即order by,指定排序字段,by *->子键名;
- limit:限制排序后返回元素的数量,表示跳过前offset个元素、返回之后的连续cnt个元素,可以实现分页功能;
- get:返回指定的字段值,get *->子键名;
- store:将排序结果存入指定位置;
事务
Transaction。
- multi:原子操作,通知Redis,接下来的若干命令属于同一事务;
- 输入若干命令,存储在命令队列中而不会被立即执行;
- exec:原子操作,通知Redis,属于同一事务的所有命令输入完成,开始执行事务;
管道
pipilining,允许Redis一次性接收多个命令、执行后一次性返回结果,减少客户端与Redis服务器的通信次数、降低往返时延。类似事务,通过原子操作multi/exec完成。
优先级队列
blpop/brpop。
高可用性(High Availability)
- 哨兵(Sentinel)
- 自动分区(Cluster)
应用场景
首先,将Redis与SQL Server/MySQL等对比一下:
- Redis的持久化是附加功能,且其flushdb、flushall命令会直接清空数据库, SQL Server/MySQL的持久化是核心功能;
- Redis全量持久数据从内存到磁盘、大数据下影响性能,SQL Server/MySQL增量持久化被修改的数据;
应用场景
- 在主页中显示最新的项目列表; - 删除和过滤:lrem; - 排行榜(Leader Board)及相关问题; - 按照用户投票和时间排序; - 过期项目处理:unix时间作为得分; - 计数(Counting Stuff):INCR,DECR命令构建计数器系统; - 特定时间内的特定项目:Redis特色特性; - 实时分析正在发生的情况,用于数据统计与防止垃圾邮件等; - Pub/Sub:发布订阅机制; - 队列(Priority Queue); - 缓存(Caching);
然后给出使用Redis中的几点注意事项:
- keys * ---> scan;
- 建议使用hash;
- expire设置key的存活时间 + volatile-lru策略;
- Redis所在机器物理内存使用最好不要超过实际内存总量的3/5;
以及通过阅读 得到的建议:

参考:; ; ;
关于Redis在C#中的辅助工具,具体参见:;
- ;;;
- ;; ;
- ;
- ;